
I have not coded an open-source project lately for the past months so I decided to think of something to learn over the weekend. Since one of the responsibilities listed on the job role that I’d be taking at Rakuten was to “continuously investigate new technology trends and check feasibility to implement in current systems (e.g. AI , Deep Learning)”, I decided to take a dip into Machine Learning. At first, I thought that I would be the one to implement the algorithms, but there are actually ready-made services and packages available. The only thing that I had to learn was how each algorithm works. There are a bunch of them, but allow me to focus on the K-Nearest Neighbors (KNN) algorithm. There’s a lot of articles, videos, and resources already that you can look up so I won’t be spending much time explaining about it.
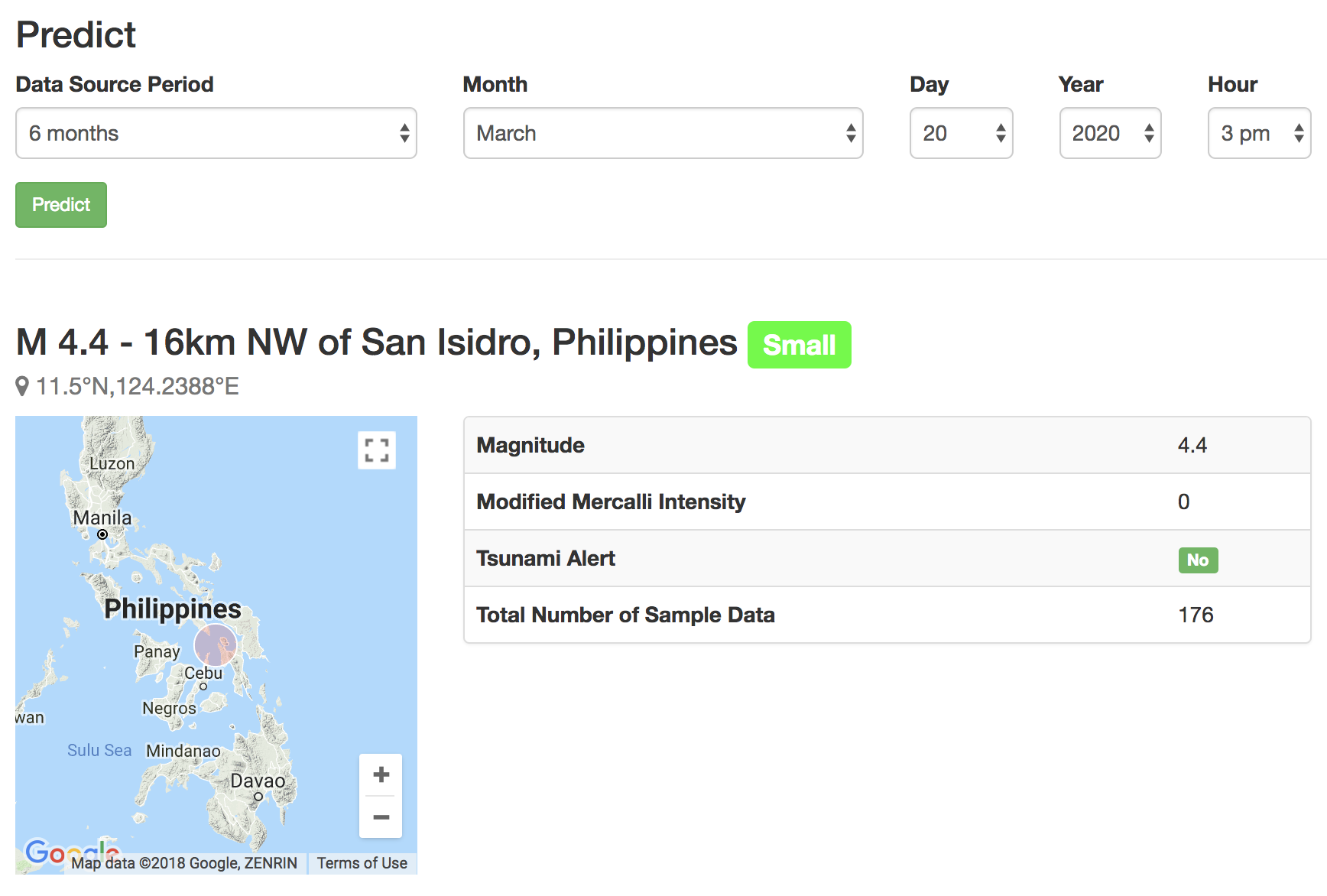
I am working on a side-project about earthquakes in the Philippines. I decided to implement what I’ve learned to this project. We will be predicting which earthquake will happen given a future date.
So first, a disclaimer. This is intended for fun only and should not be used as a reference.
For my sample data, I used two values. X is the weekday, and Y is the hour. I know that my examples aren’t the best, but I will be using it for this specific implementation. Here’s the output of my 4-hour hackathon in a nearby coffee shop last Saturday. You can play around at https://earthquake.gundamserver.com/predict.
I am currently taking a course on Machine Learning at Udemy. I’m now at the Apriori algorithm, which is interesting because of the association rule learning. One useful example is that it can “recommend” items to a user based on the items being checked out. Example, users who bought X also bought Y.
(page logo from: https://www.wordstream.com/blog/ws/2017/07/28/machine-learning-applications)